The State of Computer Vision in 2020
Computer vision has made enormous strides in the last ten years and is now being used throughout our lives. From applications in healthcare (e.g. identifying anomalies in medical images), to transportation (e.g. somewhat autonomous cars, or some of the more advanced safety features), to retail (e.g. tracking shopper behavior through a store), to social media (creepily identifying the friends in your photos), computer vision is now all around us. And, applications for computer vision will continue to grow as capabilities grow.
But, what do we mean when we say computer vision? And, where are we at today in terms of capability?
The Basic Tasks of Computer Vision
Computer vision is broad term for many different capabilities. However, it can largely be summarized by three basic tasks: object detection, object classification, and object tracking.
Object detection involves identifying that an object exists within a photo (often visualized by drawing a box around the object).

Object classification involves telling what an object is. So, for example, the algorithm would take in the picture below and output that it was a cat.

Finally, object tracking involves identifying an object, then tracking it through a moving video. See below for an example of an algorithm tracking cars through an intersection.

So, we have the three basic tasks of computer vision: detection, classification, and tracking. So, the natural next question is — how good are computers at doing each of these today?
What is the “State of Computer Vision” today?
Classification
Classification is a problem that received a ton of attention in the early to mid-part of this decade, partially due to the ImageNet dataset. ImageNet was created by AI researcher Fei-Fei Li, who at the time was an associate professor at Stanford. She conceived an idea to generate a massive dataset of labelled images, classified through Amazon’s Mechanical Turk service (i.e. classified by people). Then, in 2011, she launched the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) to both encourage and track progress in image classification.
In this competition, AI researchers would submit models that classified images into categories. And, this was not a simple classification. These models would be categorizing 1000s of images into any one of hundreds of detailed categories. For this task, it is estimated that human error is around 5%.
Now, that may sound way too high to you — after all, when was the last time that you saw a picture of a dog and didn’t know it was a dog? But, the categories in this competition were very detailed. For example, the models didn’t just need to classify a “dog”, but also had to classify the dog into 1 of ~100 different breeds. So, you can see how humans could miss 5% of these classifications.
As you can see in the image below, computers have gotten very good at classification. In 2011, the winning model had an error rate of almost 30%. This error rate had actually been relatively stable over the previous few decades.
Then, in 2012, deep learning arrived on the scene, and knocked 10 pts off the best algorithms in the world. From there, progress was made rapidly. By 2015, the error rate was down to 3%. In 2017, it was 2%.
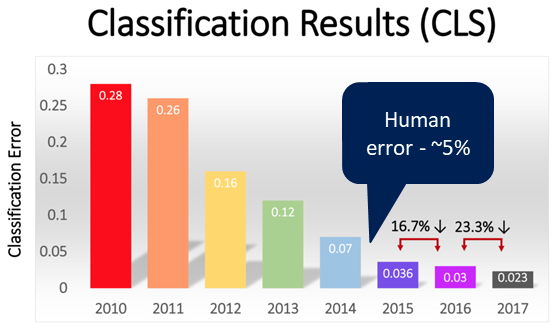
This performance is even more impressive when you consider that these neural networks needed to classify images into 100s of different categories — they were “general” algorithms. There are no “free lunches” in AI, so building a model to optimize for general performance should reduce ability in specific performance. In contrast, imagine an algorithm that solely must classify an object as “human” or “not human” (for example, this would be the sort of algorithm used at a department store to determine how many people had entered the store). This model should be able to reach even greater classification accuracy than those seen above (or, the same level of accuracy at much higher efficiency).
The ImageNet is still maintained today, as a resource for researchers. It is truly a massive dataset, with a goal to provide at least 1,000 images for each of 80,000 “synsets”, which are words or phrases describing a unique concept (for context on how comprehensive this is, the English language has ~170K words, according to the Oxford English dictionary).
Anyway, in summary, fixed image classification is largely a solved problem. If you want to build a classifier, there are many open source models you can download and train, and you would achieve a high level of accuracy.
So, what are folks working on in classification? Well, there are some problems that require ultra-high accuracy in classification (think medical imaging). In these situations, although algorithms have seemingly gotten to the point of equaling medical professionals, there are further gains by pushing the accuracy even higher. Additionally, these algorithms can be computationally intensive, because medical images are extremely high resolution. So, figuring out ways to deliver similar accuracy with lighter models is important. Finally, classification gets more challenging when it is combined with live video (think identifying a certain hand gesture). So, there are plenty of problems still to work on in classification!
Detection
Detection has similarly progressed significantly since the early part of this decade, and we can see this in the results of the PASCAL VOC competition. PASCAL is a “network of excellence” funded by the European Union, and from 2005 to 2012 they ran a competition called the “Visual Object Classes”, or VOC. And, although this competition ended in 2012, new models have continued to be tested against this dataset, to see how they have improved. And, as you can see in the chart below, they have improved significantly!

So, in 2007, models could detect objects (and classify into 20 categories — in the real world, detection typically includes “detection + classification”) with a “mean average precision” of 20%. Precision is a measure of how many “false positives” exist in my predictions — basically, the likelihood that when my model predicts “there is a cat right there” that there is actually a cat right there (mean average precision is a complicated averaging calculation that we don’t need to go into here, the definition is here if you are interested). In 2018, models achieved MAP of ~90%. That is incredible progress in just over 10 years!
However, I should note one thing here — the above improvement is on stationary images.
Detection gets much more difficult on video, both because because there are imperfections in the video image, such as motion blur, and because the algorithm needs to work more quickly (real time video happens at ~30 frames per second, meaning an image must be processed every .03 seconds to detect in real time). Even if your application doesn’t require real time processing (for example, if you can process video over night and get the insights the next day), processing all those frames in a reasonable time period requires a fairly quick model.
To further understand the challenge of real time video, see below how average precision drops off as the frames per second (FPS) increase (the various lines are popular algorithms for object detection in video).

The most popular of the “open source video detection” algorithms is YOLO, which stands for “You Only Look Once”. Basically, YOLO is able to process an image with only a single forward pass through the neural network, proposing bonding boxes (detection) and class probabilities (classification) simultaneously, versus other approaches that do this in multiple steps. This makes YOLO extremely fast — but, as you can see in the chart above, you do sacrifice some precision.
Finally, another exciting frontier in detection is detection in 3D. Video and images are obviously 2D, but imaging technology like stereo cameras and LIDAR provide 3D input, which could improve detection accuracy in the real world. Earlier this year, Facebook release Pytorch3D, a library for building 3D deep learning models.
Anyway, in summary, although object detection in fixed, stationary images has been well-developed, there remains work to do in video detection, particularly in use cases that require processing at high FPS. Why is detection on video so important? Well, that takes us to tracking.
Tracking
Tracking is the most difficult of the 3 basic tasks of computer vision. Why is tracking so difficult? Well, essentially it is a combination of detection and classification, with an additional variable (time) added in.
Let’s consider a basic tracking task — tracking a bunch of individuals walking through a mall. To do this, we need to combine two models.
The first is a highly accurate detection / classification model. We need to detect and classify not just that this is a person, but that this is a person distinct from all other people in the video. Our algorithm must recognize enough about this person such that it can accurately say that this is the same person later in the video, even if the person disappeared for 10 seconds. And, it must do all this at “real-time speed”, which, as we discussed in the last section, is difficult.
In single object tracking, this “identity” model may be enough to perform high accuracy tracking. But in multi-object tracking, we must also incorporate a second model, the “motion model”. This will help us predict where an object will appear, based on its motion in previous frames, and thus we can detect the object with higher confidence. However, a motion model alone will likely fail, as objects frequently change direction or speed abruptly, or are occluded by other objects.
Tracking is made even more difficult when constrained by privacy concerns. As anyone who has unlocked an iPhone 10, or gone through customs in the US, knows, facial recognition can be surprisingly accurate. However, many startups in the space today are not building facial recognition capabilities, as they anticipate legislation (like Portland just passed) that will restrict the use of facial recognition in public places. They also have a respect for basic privacy. So, imagine tracking people around a video without being able to look at their faces, and you can understand a bit of the difficulty these algorithms face.
So, how do we measure the success of object tracking algorithms? Well, you guessed it — there is a contest! In this case, the MOT challenge, or Multiple Object Tracking benchmark.
The MOT challenge provides several videos of people walking in various locales, lighting, etc. The various models compete to best detect and track people through a video. The models are graded on “MOTA” which is a measure of 3 different types of errors — false positives, missed targets (i.e. false negatives), and identity switches. MOTA is calculated as 1 — (FP + FN + IS) / Ground Truth. So, 100% is perfect, and MOTA can technically be negative (if you had multiple errors on the same object).
So how do people do on this challenge today? Well, in 2020, the top performing model achieved an average MOTA of 56.3%, but MOTA varies widely depending on the video.
To see this, consider the snapshot of the below video — on this video, algorithms in the contest averaged a MOTA of almost 70% (up from 63% in 2019).

Although this video is a bit dark, there is a clear view of each person, and due to the overhead nature of the shot, it is less likely a person will become occluded. There is also an absence of “non-people” objects in this video, reducing the likelihood of false positives.
Now consider the next video — on this video, algorithms averaged a MOTA of only 18% (up from 14% in 2019).

What makes this video so hard? Well, to begin, it is a side angle, so the chance for occlusions is higher. Additionally, there are lots of objects in this video (e.g. tents, strollers, chairs) that are not people.
So, where are these algorithms struggling? Well, most of the algorithms have very high precision, which means they are avoiding false positives. However, each of these algorithms has low recall (50–60%), which means a high number of false negatives. They are detecting just over half of the people in the shot on any one frame. Now, in video, you can compensate for missing an object in one frame by picking them up in the next frame. So, this doesn’t mean that the algorithm is missing ½ of the people walking through the video. It just means they only pick up each person, on average, every other frame. So, for some applications (e.g. people counting) this might work fine. For others (e.g. understanding what activity each person is doing), missing frames might make this more difficult.
The Next Frontier
So, we have talked about a few things that are still “hard” in computer vision. But, to try to summarize it simply: high fidelity detection and classification from video, particularly if it requires processing in real time. This is both a hardware and a software problem, and many companies are working to advance the capabilities of systems here.
However, in the meantime, there are hundreds of use cases that computer vision is well-suited to address right now, particularly given the advances over the last few years. So, expect to continue to see computer vision penetrate enterprise and consumer use cases, as entrepreneurs combine state-of-the-art technology with deep knowledge of specific use cases to build compelling solutions.









